
1. Ausgangslage
Die Ausgangslage bezieht sich auf die Universitätsbibliothek „Georgius Agricola“ der TU Bergakademie Freiberg und den Ablauf zur Erschließung von Neuerwerbungen. Das vorgestellte Tool ALIMA (AI-powered Library Indexing and Metadata Assignment ) wird von Dr. Conrad Hübler, Fachreferent für Naturwissenschaften der Universitätsbibliothek und Postdoc im Institut für Physikalische Chemie, entwickelt. Das Tool wurde erstmals in einem Online-Meeting der DINI AG KI am 9. April 2025 vorgestellt.
Zu den traditionellen Kernaufgaben des Fachreferats an Bibliotheken gehört das Erschließen von Neuerwerbungen wie Fachbüchern, Zeitschriftenartikeln oder Hochschulschriften. Erschlossene Medien lassen sich schließlich leichter auffinden, da sie einem Fachgebiet zugeordnet wurden und ihre Inhalte durch Schlagworte konkretisiert sind.
Das klassifikatorische Erschließen umfasst die Zuordnung der Medien zu konkreten Fachbereichen, die durch bestimmte Systematiken wie die Dezimalklassifikation (DK) organisiert sind. In der Geschichte der Universitätsbibliothek der TU Bergakademie Freiberg wurde die DK gewählt, die dafür notwendigen gedruckten Register angeschafft und der Bibliotheksbestand entsprechend katalogisiert; anschließend wurde die Systematik jedoch nicht weiter angepasst. Als Resultat ergaben sich fachlich veraltete Systematiken, die noch immer verwendet werden. Eine Aktualisierung auf die moderne Regensburger Verbundklassifikation (RVK) ist für neu eingerichtete Fachgebiete realisiert worden, der übrige Bestand blieb aber unangetastet. Damit wird die klassifikatorische Erschließung überwiegend mit nur teilweise digitalisierten und sonst abgenutzten Druckexemplaren realisiert, in denen für jedes relevante Fachgebiet des zu erschließenden Textes die passende Klassifikation händisch gesucht werden muss. Für den Fachbereich Geowissenschaften wird seit Jahren eine eigene DK-Datenbank verwendet, die händisch gepflegt wird.

Die verbale Erschließung umfasst die Zuordnung von aussagekräftigen Schlagworten zum Textinhalt. Dafür kommt kontrolliertes Vokabular der Gemeinsamen Normdatei (GND) zum Einsatz, die von der Deutschen Nationalbibliothek (DNB) und den angeschlossenen Bibliotheksverbünden kuratiert wird. Über die OGND-Websuche bietet der Bibliotheksservice-Zentrum Baden-Württemberg (BSZ) Möglichkeiten zur Recherche in der Datenbank der GND an. In der Datenbank sind die erlaubten Schlagworte, die zugeordneten Synonyme sowie die Hierarchie der Schlagworte hinterlegt und einer eindeutigen GND-ID zugeordnet.
Das Erschließen eines Sachtextes erfordert nicht nur Kenntnis der bibliothekarischen Struktur und die korrekte Verwendung des kontrollierten Vokabulars, sondern auch entsprechendes Fachwissen, da zugeordnete Schlagworte den Inhalt korrekt widerspiegeln müssen.
Schwierigkeiten in der Fachreferatsarbeit ergeben sich durch zunehmend interdisziplinäre Forschungsbereiche, die eine immer breitere klassifikatorische Einordnung der Fachtexte erfordern, bei gleichzeitig starren und teilweise veralteten Systematiken. Dadurch wird es selbst für Fachpersonal immer zeitaufwendiger, sich in alle relevanten Themen für das Erschließen der Fachtexte einzuarbeiten und anschließend sowohl die gedruckten Register als auch die Online-Datenbanken zur Recherche für die korrekte Einordnung zu Rate zu ziehen.
Eine Alternative böte die automatisierte und maschinelle Erschließung der Fachtexte. Die Verwendung von großen Sprachmodellen (Large Language Models, LLM) für die Erschließung ist dabei naheliegend, jedoch ergeben sich verschiedene Probleme: Die erste Herausforderung besteht darin, dass das LLM grundsätzlich in der Lage sein sollte, den vorliegenden Fachtext in einen passenden Kontext zu setzen. Doch selbst wenn das LLM den Text richtig einordnen kann, ist zweitens eine korrekte Zuordnung zu dem kontrollierten Vokabular der Schlagworte sowie zu den Klassifikatoren kein Automatismus. Obwohl LLMs eine praktische Anwendung von künstlicher Intelligenz sind, sind die zugrundeliegenden Methoden keineswegs ausreichend intelligent, sondern erstellen ihren Text auf Basis von Wahrscheinlichkeiten und Plausibilität. Ist ein passendes kontrolliertes Schlagwort nicht verfügbar, wird eines erfunden. Dieses sogenannte Halluzinieren von Informationen ist ein typisches Problem von LLMs, das immer dann auftritt, wenn die inhaltlich korrekte Antwort nicht im Datensatz enthalten ist und stattdessen die nächstwahrscheinliche Antwort gewählt wird.
Zwar ließe sich das Problem umgehen, indem ein LLM extra trainiert wird, um die Inhalte der GND und der Klassifikationen zu kennen, gleichzeitig sollte aber die ursprüngliche Fähigkeit des LLMs, den Text und Kontext korrekt zu erkennen, erhalten bleiben. Das Training eines solchen Modells wäre sehr ressourcenaufwendig und müsste nach Updates der GND-Daten und Klassifikationen wiederholt werden. Auf rechtliche Aspekte, Zugänglichkeit zu Trainingsdaten und die gesamte Infrastruktur zum Training soll hierbei nicht weiter eingegangen werden. Ein weiteres Hindernis in diesem Zusammenhang ist das Problem der extremen Multi-Label-Klassifikation (XMLC)[1, 2 3, 4].
Eine Alternative zum neuen Training von LLMs ist ein Ansatz, der als Retrieval Augmented Generation (RAG) bezeichnet wird. Bei diesem wird ein bereits trainiertes LLM mit zusätzlichen Kontextinformationen ausgestattet, auf deren Basis das LLM eine Antwort generiert. Diese Kontextinformationen können dabei ohne Schwierigkeiten aktualisiert werden. Eine Möglichkeit besteht darin, dem LLM für die Erschließung von Texten eine Datenbank mit dem Inhalt der Klassifikationen und genormten Schlagworten bereitzustellen, wobei die vollständige Datenmenge als Kontextinformationen zu umfangreich wäre.
2. Lösungsweg
Im Folgenden wird die Umsetzung einer maschinellen Sacherschließung im Programm ALIMA skizziert. Das Werkzeug ist in Python geschrieben und verwendet Qt6 als Bibliothek, um eine grafische Benutzeroberfläche zu realisieren. Für die Programmierarbeit wurde extensiv auf Claude 3.5 und Claude 3.7 Sonnet gesetzt, da sich dieses LLM für die Entwicklung von Quelltext sehr gut eignet. Die Verwendung von LLMs ermöglicht es, sehr zeitgünstig verschiedene Ansätze zu implementieren und auszutesten. So wurde mit der Entwicklung im Januar 2025 begonnen und ein erster Prototyp innerhalb der ersten Woche bereitgestellt. Die Weiterentwicklung war dabei nicht so sehr von der zeitlichen Umsetzung der Programmierung abhängig, da neue Ideen sehr effektiv durch KI-Hilfe getestet werden konnten. Für die finale Implementierung und Zusammenführung des KI-generierten Codes ist Programmierarbeit jedoch weiterhin notwendig, da auch die technischen Fähigkeiten der KIs begrenzt sind.
Aus dem Entwicklungsprozess hat sich ein Arbeitsprotokoll ergeben, das bereits erfolgreich in einem Python/Qt6-Tool implementiert wurde. Die Entwicklung ist per Git auf GitHub [5, 6] dokumentiert und nachvollziehbar.
Das Arbeitsprotokoll für die maschinelle Erschließung:
- Für einen Zielttext (Abstrakt, Volltext, Inhaltsverzeichnis) werden unter Zuhilfenahme eines LLMs freie Schlagworte gefunden (Prompt 1).
- Volltextsuche der freien Schlagworte im HBZ-Katalog (Lobid-API) und der GND-Datenbank (Webpage + Extraktion mit Beautiful-Soup), automatisches Füllen einer lokalen GND-Datenbank (Schlagwort und GND-ID).
- Alternativ: Suche der Treffer zu den Schlagworten im Katalog der TU Bergakademie Freiberg (TUBAF) und Extraktion der Schlagworte und Abgleich mit der lokalen Datenbank.
- Das Kontextfenster für den vorliegenden Zieltext ergibt sich aus den Treffern der vorherigen Suche. Die verbale Erschließung erfolgt dann mit einem weiteren Prompt (Prompt 2). Das LLM wird hierbei explizit aufgefordert, eine Zuordnung der Schlagworte zu den GND-IDs herzustellen, um Halluzinationen zu minimieren.
- Die gefundenen GND-konformen Schlagworte bilden die Grundlage für eine weitere Katalogsuche nach klassifikatorischer Erschließung auf der Basis des Bibliothekskataloges. Für jedes GND-Schlagwort werden entsprechende DK-Zuordnungen aus dem Katalog extrahiert. Anschließend kann ein weiterer Prompt (Prompt 3) verwendet werden, um mit dem Ausschnitt aus dem Bibliothekskatalog die Klassifikation auf der Basis des Zieltextes durchzuführen.
Die Abfrage im Katalog wird derzeit noch über eine Websuche und das Analysieren des HTML-Textes mit dem python-Tool Beautiful-Soup realisiert, doch eine API-Anfrage konnte bereits getestet werden. Durch die Verwendung von LLMs bei der Programmierung konnten kleinteilige Arbeiten wie die Ermittlung des passenden Beautiful-Soup-Ansatzes oder die Anbindung verschiedener Provider für LLMs (OpenAI/ChatGPT, Google Generative, Ollama) ausgelagert werden.
3. Ergebnis
Aktuell werden sehr gute Ergebnisse mit Gemini 1.5 und 2 erzielt. Technisch ist die Verwendung von Google dabei am einfachsten, da ein API-Key mit begrenztem Abfragevolumen kostenfrei erhältlich ist, wobei der Datenschutz bei frei abrufbaren Inhalten (GND, Bibliothekskatalog) weniger relevant ist. Durch die Verwendung von Ollama können lokale LLMs für die Erschließung verwendet werden bzw. alternativ bietet die GWDG für Hochschulen deutschlandweit einen API-Zugang zu universitär gehosteten LLMs an, die über die OpenAI-Schnittstelle in dem Erschließungstool verwendet werden können. Hier zeigen erste Tests, dass Gemma 3 27B als freies LLM eine gute Alternative zu Gemini ist.
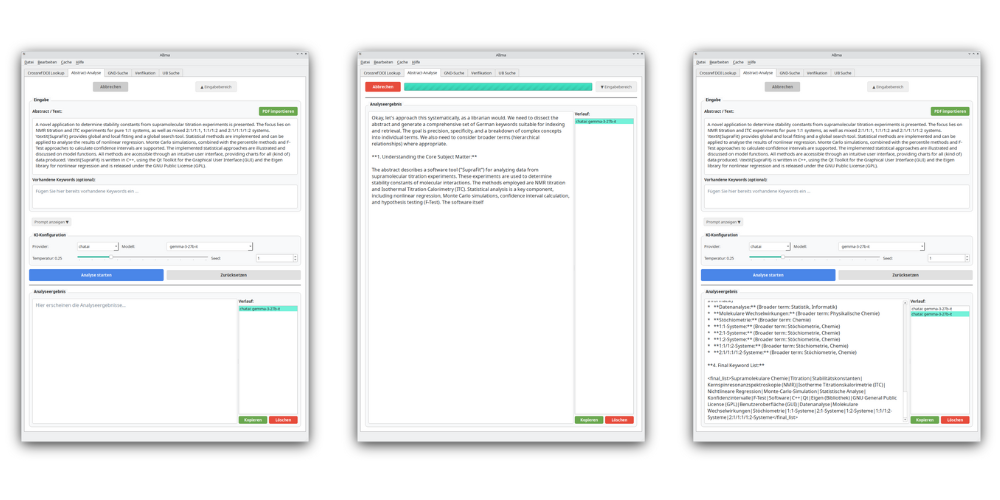
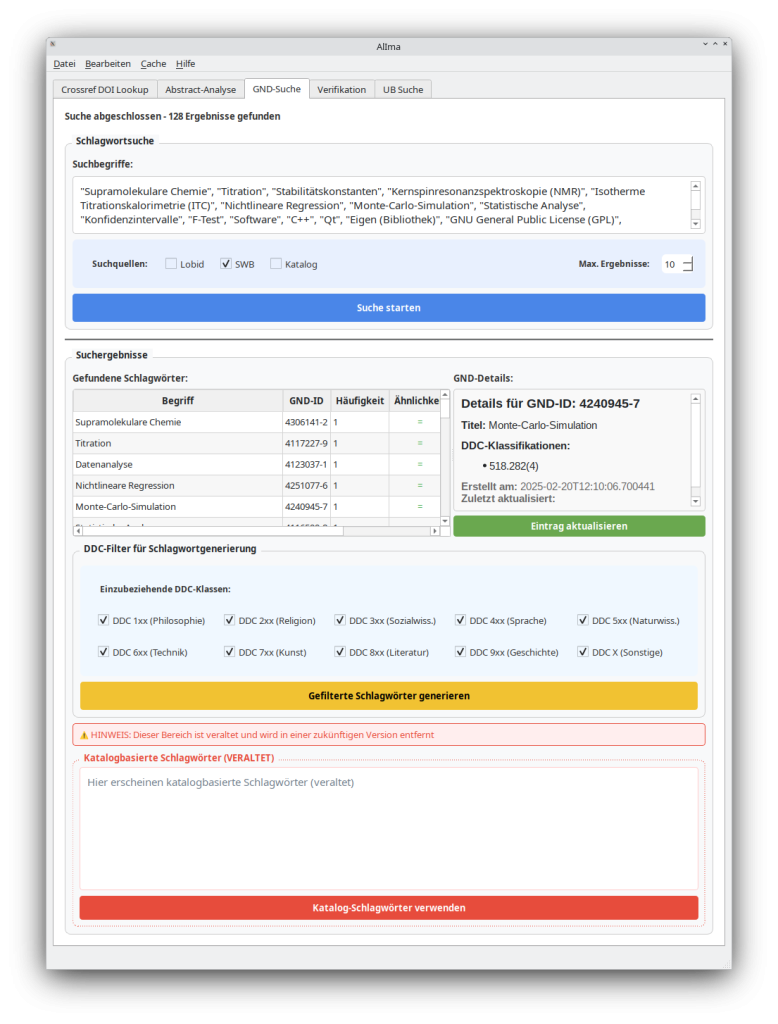
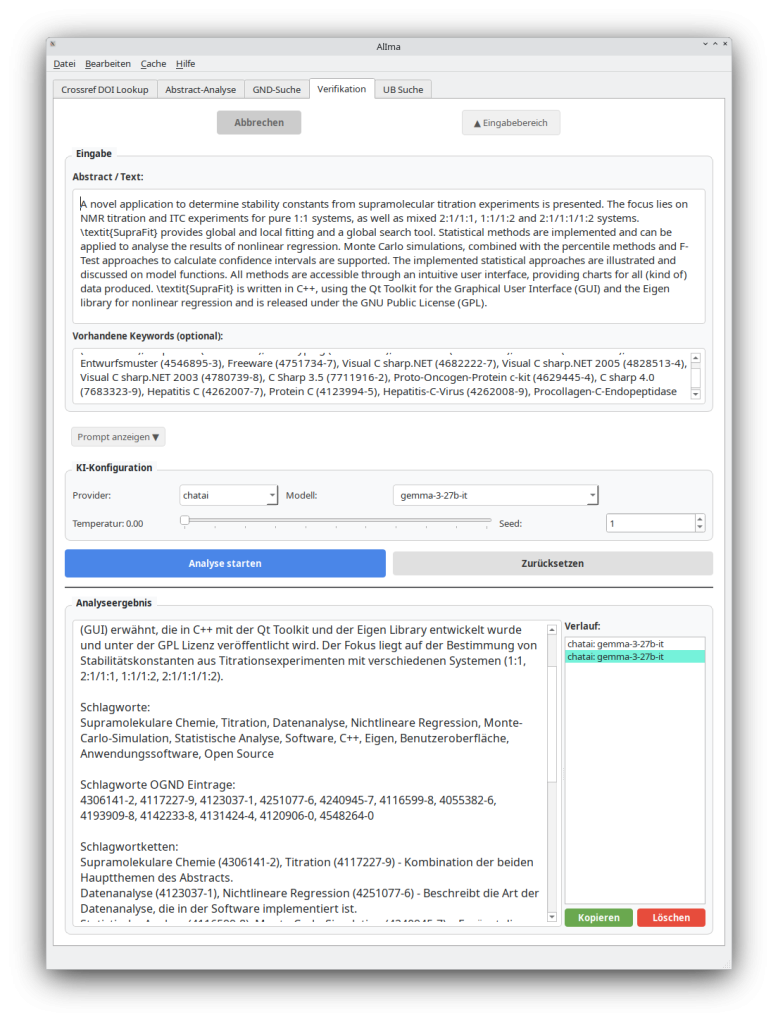
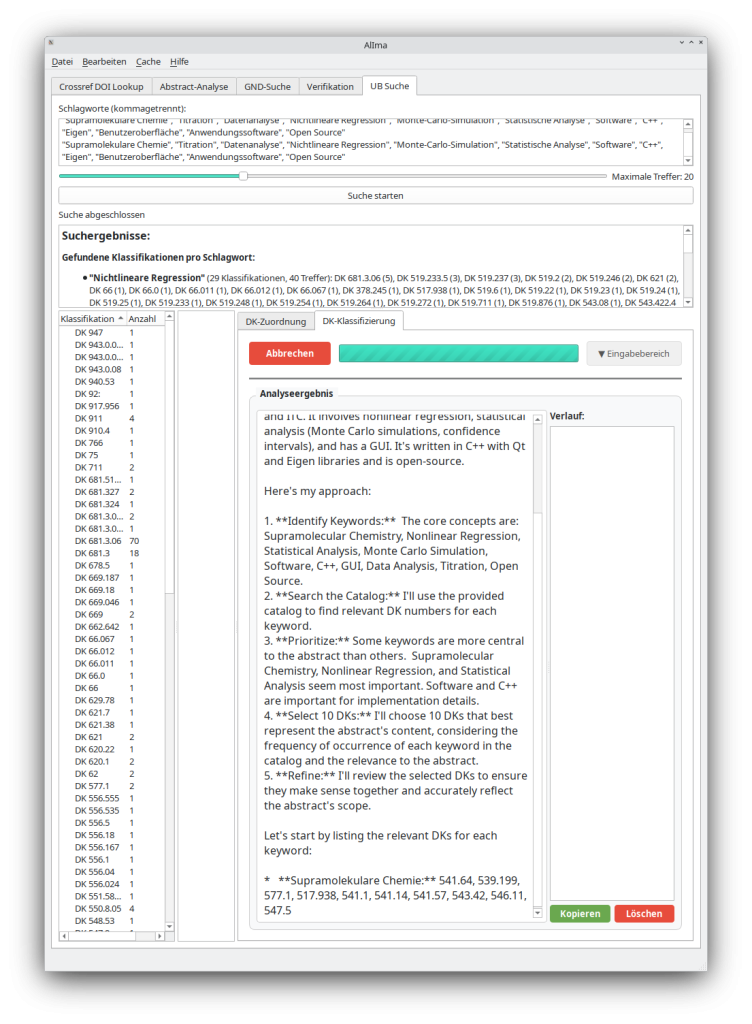
3.1 Modelle
Die Qualität der Verschlagwortung hängt sehr von der Größe der Modelle ab. Während die Zuordnung von freien Schlagworten auch mit kleineren Modellen erfolgen kann (< 70 Milliarden Parameter, < 70B), sind aufgrund des umfangreichen Kontextes bei der Zuordnung von kontrolliertem Vokabular Modelle mit größerem Kontextfenster notwendig. Versuche mit DeepSeek R1 Distilled 70B zeigen, dass ein solches Modell durchaus in der Lage ist, zufriedenstellende Verschlagwortung zu liefern, während kleinere Modelle den Zieltext ignorieren und lediglich eine Analyse der bereitgestellten Schlagworte durchführen.
4. Nächste Schritte
Die Proof-of-Concept-Umsetzung zeigt, dass mit geeigneten Modellen, angepassten Prompts und kuratierten Kontextinformationen eine Sacherschließung durch LLMs realisiert werden kann. Derzeit dient das Tool bereits als Unterstützung für die Fachreferatsarbeit an der Universitätsbibliothek der TU Bergakademie Freiberg und wird fortwährend weiterentwickelt. Dabei sind effizientes Speichern und Zuordnen der GND-Schlagworte zur Klassifikation und die Integration der umfangreichen DK-Datenbank im Fachbereich Geowissenschaften geplant. Die Justierung der Prompts und Systemprompts sowie das Feinabstimmen der Prompts und Parameter für die jeweiligen verfügbaren Modelle bieten weiteres Potential für Verbesserungen.
Referenzen:
[1] https://www.dnb.de/DE/Professionell/ProjekteKooperationen/Projekte/KI/ki_node.html
[2] https://blog.dnb.de/texte-erschliessen-mit-ki/
[3] Poley, C., Uhlmann, S., Busse, F., Jacobs, J.-H., Kähler, M., Nagelschmidt, M., & Schumacher, M. (2025). Automatic Subject Cataloguing at the German National Library. LIBER Quarterly: The Journal of the Association of European Research Libraries, 35(1), 1–29. https://doi.org/10.53377/lq.19422
[4] D’Souza, J., Sadruddin, S., Israel, H., Begoin, M., & Slawig, D. (2025). SemEval-2025 Task 5: LLMs4Subjects – LLM-based Automated Subject Tagging for a National Technical Library’s Open-Access Catalog. Proceedings of the 19th International Workshop on Semantic Evaluation (SemEval-2025), 1082–1095. https://aclanthology.org/2025.semeval2025-1.139
[5] https://github.com/conradhuebler/ALIMA
[6] Conrad Hübler. (2025). conradhuebler/ALIMA: v0.0.1-alpha (v0.0.1). Zenodo. https://doi.org/10.5281/zenodo.15281300
Autor
Conrad Hübler hat an der TU Freiberg Chemie studiert und wurde in theoretischer Chemie promoviert. Seit 2022 ist er als Fachreferent für Chemie, Physik und Biowissenschaften sowie als Mitglied des Open Science Teams an der Universitätsbibliothek der TU Freiberg beschäftigt und seit 2023 auch im Institut für Physikalische Chemie als Postdoc tätig.
Zitiervorschlag
Hübler, Conrad. “ALIMA – Sacherschließung unterstützt durch große Sprachmodelle. Ein Werkstattbericht.” Deutsche Initiative für Netzwerkinformation, 2025, https://doi.org/10.57689/DINI-BLOG.20250519.
Anhang
Prompt 1:
Du bist ein korrekter und fachlich versierter Bibliothekar. Basierend auf folgendem Abstract und Keywords, schlage passende vollständig deutsche Schlagworte vor. Diese Schlagworte sollen als Suchbegriffe dienen, um in kontrolliertem Vokabular zu suchen. Daher sollen für spezielle Begriffe zusätzlich noch die Oberbegriffe geliefert werden. Zerlege weiterhin bei komplexen Themen, zerlege die Schlagworte in einzelne und verhindere damit unnötig zusammengesetzte Schlagworte. Als Beispiel Dampfschifffahrtkapitän -> Dampfschifffahrt, Kapitän und Thermodynamischer Template-Effekt -> Thermodynamik, Template-Effekt.
Abstract:
Vorhandene Keywords:
Keine Keywords vorhanden
Bitte gib nur eine Liste deutscher Schlagworte zurück, die für eine bibliothekarische Erschließung geeignet sind.
Die Schlagworte sollten möglichst präzise und spezifisch sein.
Prompt 2:
Du bist ein korrekter Bibliothekar, der aus einer Liste von OGND-Schlagworten alle heraussuchen soll, die den folgenden Text beschreiben. Es dürfen nur Schlagworte verwendet werden, die in der Liste auftauchen. Sollten für spezielle Konzepte keine konkreten Schlagworte vorhanden sein, verwende nach Möglichkeit gelieferte Oberbegriffe, auch wenn sie allgemein sind. Kombiniere Schlagworte in Ketten, um spezielle Konzepte genauer zu spezifizieren, insbesondere wenn die verfügbaren Schlagworte allgemein sind. Führe auch keine weitere Erschließung durch, außer in der abschließenden Diskussion, in der auch nicht gefundene Konzepte diskutiert werden können.
Abstract:
Zur Auswahl stehende GND-Schlagworte:
Bitte gib deine Antwort in folgendem Format:
ANALYSE:
[Deine qualitative Analyse der Verschlagwortung]
Schlagworte:
[Liste der passende Schlagwort aus dem Prompt – bitte kommagetrennt. ***Nutze keine Synonyme oder alternative Schreibweisen/Formulierungen***]
Schlagworte OGND Eintrage:
[Liste der passende Konzepte mit der zugehörigen OGND-ID aus dem Prompt – bitte kommagetrennt]
Schlagwortketten:
[Nutze Kombinationen von OGND-Schlagworten um bestimmte Themenbereiche konkret zu beschreiben oder um Konzepte, die durch ein Schlagwort nicht korrekt abgedeckt sind. Trenne die Schlagworte (mit GND-ID) in den Ketten mit Komma. Nimm für jede Schlagwortkette eine neue Zeile – Kommentiere zu jeder Schlagwortkette kurz, wieso diese passend ist]
FEHLENDE KONZEPTE:
[Liste von Konzepten, die noch nicht durch GND abgedeckt sind]
KONKRETE FEHLENDE OBERBEGRIFFE BZW. SCHLAGWORTE:
[Kommatagetrennte Liste von Oberbegriffen, die die fehlenden Konzepte abdecken könnten]
Prompt 3:
Du bist ein korrekter Bibliothekar und sollst einen Abstrakt, der bereits verschlagwortet wurde, mit der Dezimalklassifikation versehen. Du hast einen Ausschnitt aus dem Bibliotheksbestand der Titel, Schlagworte und DKs umfasst.
Wähle 10 passende DKs für den Abstrakt auf der Basis der Suche aus, die Titel, Schlagworte und DKs umfasst!
**Ausschnitt aus dem Bibliotheksbestand:**
Keine Keywords vorhanden
Dieser Beitrag – ausgenommen Zitate und anderweitig gekennzeichnete Teile – ist lizenziert unter der Creative Commons Namensnennung 4.0 International Lizenz (CC BY 4.0).
